RCDb (now named Watchwith) is tagging thousands of movies and TV shows with metadata that identifies time spans of actors/characters, products, scenes, music, and more. A typical feature length movie could have several thousand of these tags describing its content. RCDb uses the term Time Data for this timeline metadata. I spent a couple years at RCDb analyzing and visualizing Time Data for QC purposes and to help evaluate various data collection methods. I also got to work with faculty and students at USC's School of Cinematic Arts for a semester, exploring ways Time Data might can be used in scholarly study of films (Movie Tagger Alpha).
A few samples of my Time Data visualization work...
MetaBubbles
I started playing with visualizing Time Data just out of curiosity (while I was busy doing my "real" job at the time, writing code for Blu-ray discs). I was lucky to have access to the metadata early in the Time Data effort, where almost any visualization work offered unexpected insight into the collection/QC process. Some byproducts of my tinkering with visuals of the metadata were tools to complement and aid human review of the metadata. One of those tools was MetaBubbler, a utility that presents Time Data synchronized in time over the corresponding video. I used the MetaBubble video to check anomalies that would appear in my visualizations. For example, there is a long stretch in The Matrix where no actors appear in the film's scene stack. That turned out to be an animation sequence. In contrast, Mamma Mia!'s scene stack has spans with a couple dozen actors or more. Viewing the MetaBubbled video, I learned that all the actors in dance scenes had been tagged. Other times, an oddity would appear in a visualization, and double checking the MetaBubble video would verify that there was a flaw in the data. MetaBubbler started as a utility to augment visualizations, and soon became a mainstay of the Time Data QC process.
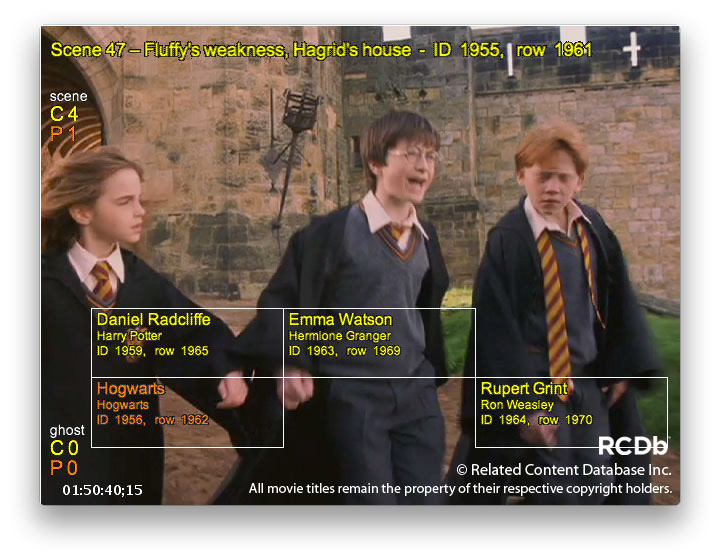
In this Mad Men MetaBubbles screenshot, actors appear in yellow and products in orange, complete with references back to the database entry for each item...

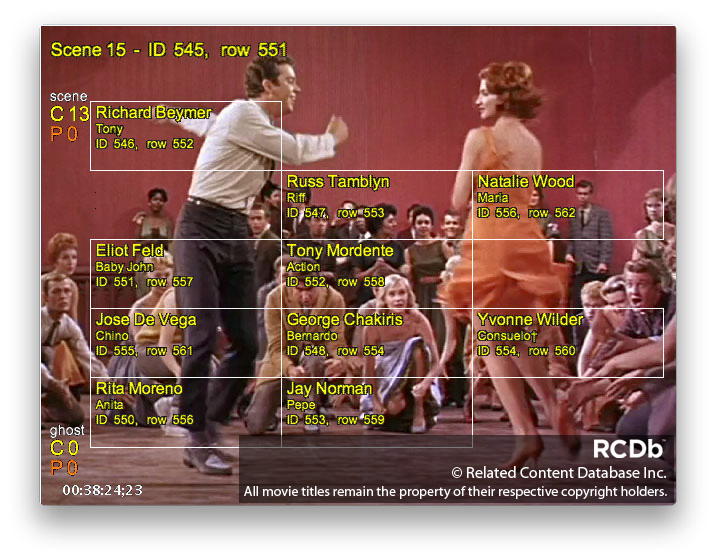
The Wild Hogs Time Data contains extensive product information. In this shot, each motorcycle model, as well as the helmet model and the sound track has been tagged...

More MetaBubbles samples from the Movie Tagger Alpha project (click below to view):
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Scene Stacks
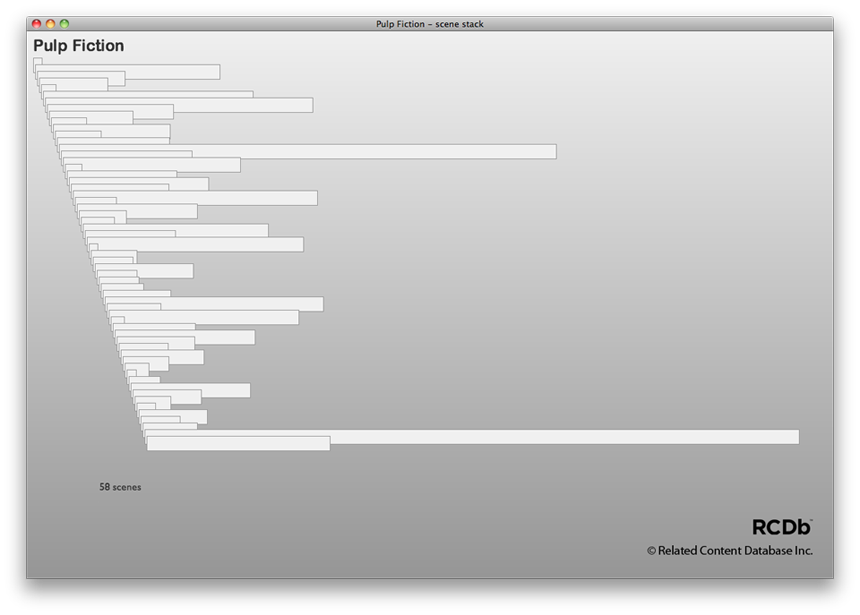
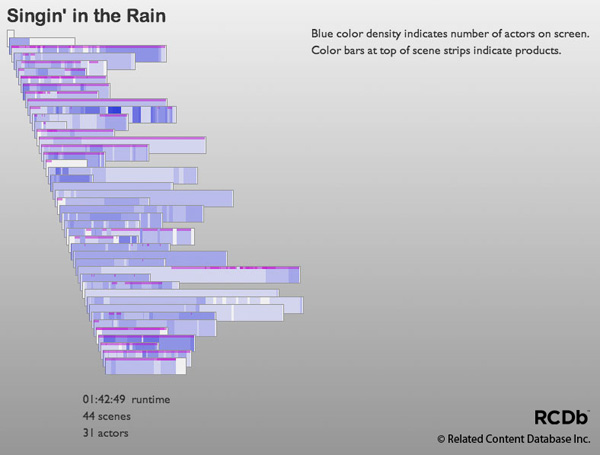
Starting with a movie timeline, Time Data partitions it by scenes:

When we stack the scenes first to last, starting at the top, we quickly gain a sense of the rhythm of the narrative by comparing scene lengths. For example, in Pulp Fiction, it appears that about half the scenes are relatively short, and there is one exceptionally long scene about a third of the way into the film. In most movies, the credit roll appears as a long "scene" at the tail of the film.
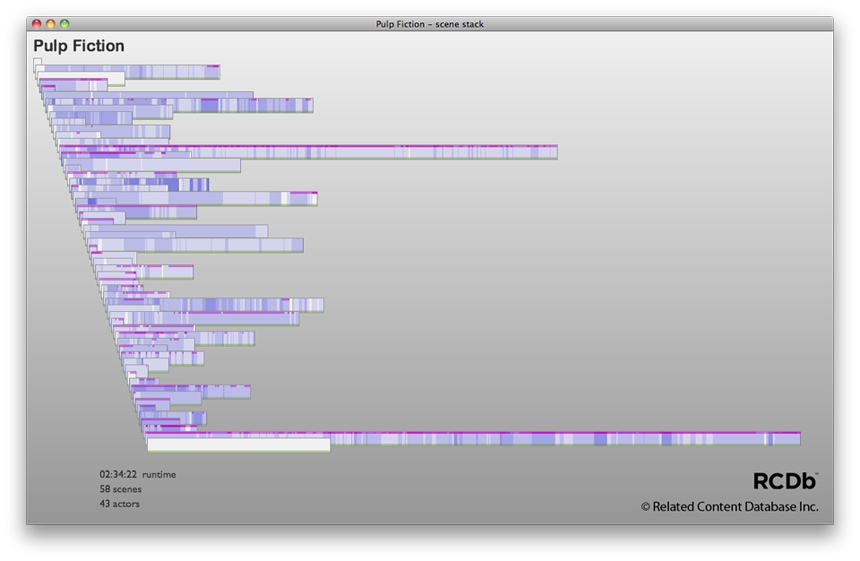
Next, we add the actor and product data to the scenes. Time Data defines the span of each distinct actor or product appearance as an event with in- and out-points, and a description. Actor spans appear in blue. The darker the blue, the more actors that appear simultaneously at that point in the film. The magenta spans along the tops of scene strips indicate the presence of products. We can see that Pulp Fiction typically has very few actors appearing at once, but there are a few brief spots packed with more actors. Also, most scenes in Pulp Fiction include identifiable products, but there are a handful with no products.
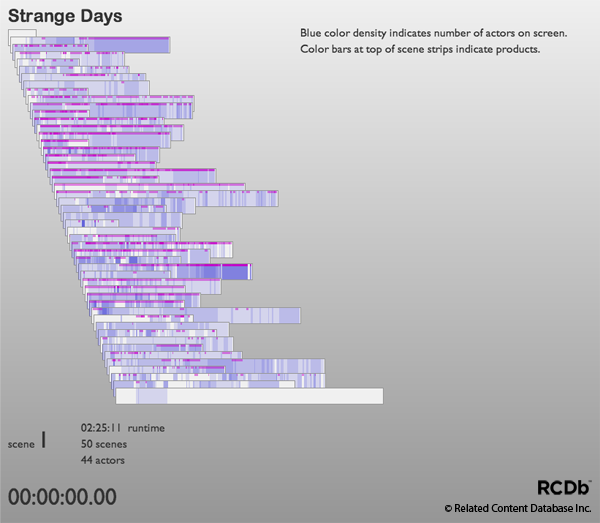
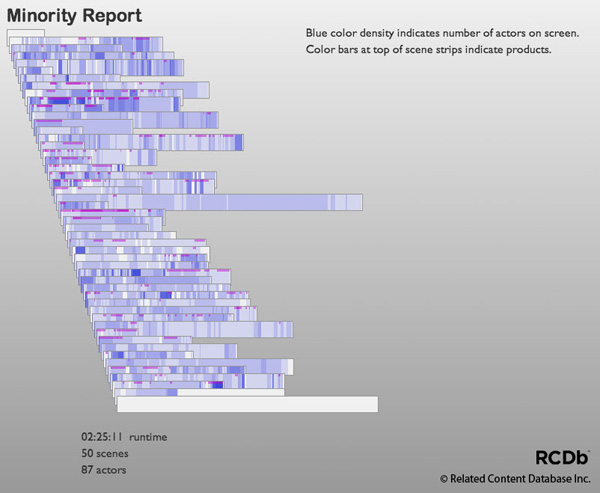
More examples of scene stacks... (click below for details)

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Big Picture
This poster shows the 1,637 titles in the dataset at the time the poster was produced, giving a sense of the historical span of the titles, and a summary glimpse of the data collected for each. The shades of blue delineate decades. We can see that the 1990s (the darkest blue, at the bottom of the poster) contained about 35% of the Time Data titles when this poster was made.

The following is a detail from the top-left of the poster. The earliest films in the Time Data collection date back to 1921. Each film is represented as a timeline strip, with marks indicating scene breaks. Each strip is labeled with the film's title, year, and scene/actor/product counts.

Some counts from this set of films:
Titles
- 1,637 titles
- min duration - 0:45:46, Everest
- med duration - 1:49:24, The Wrestler
- max duration - 4:11:15, Cleopatra
Scenes
- 85,864 scenes
- min - 14 scenes, Tarzan - The Ape Man
- med - 50 scenes, Brothers
- max - 107 scenes, The Lord of the Rings: The Return of the King
Actors
- 1,846,174 actor events
- min - 72 events, Richard Pryor - Live on Sunset Strip
- med - 1,055 events, Duplicity
- max - 3,892, D2 - The Mighty Ducks
Products
- 370, 433 product events
- min - 9 events, Cleopatra, Tarzan - The Ape Man, Mulan
- med - 181 events, In the Valley of Elah
- max - 1,561 events, The Blind Side
Overview
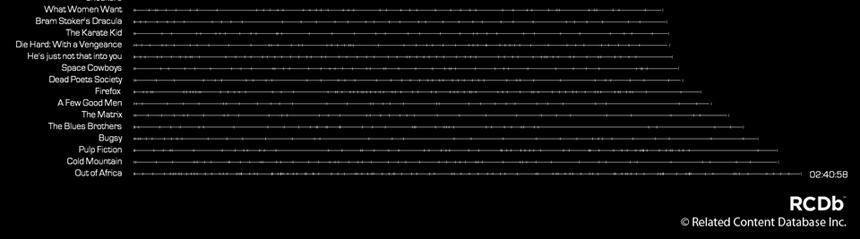
Early in the Time Data project, when we had tagged only 87 films, I sorted them by duration and plotted each film's timeline, with marks at scene breaks. In this set, the durations range from around 75 minutes (Pokemon: The First Movie) to nearly 161 minutes (Out of Africa). As you might expect, children's films tend to appear on short end of this list.

The surprising thing thing with this graph is how nearly linear the progression of film durations is for most of the films. Then, at around 130 minutes durations, the final 10% of the films burst into longer durations.
Co-occurrence Diagrams
One indicator of relationships among characters is how much time they appear simultaneously in a film, which is easy to calculate from Time Data. The following network diagram shows co-occurrences of actors in Minority Report. Actor nodes are sized according to their total screen-time in the film. John Anderton, played by Tom Cruise, is the central character, appearing more than twice as often than any other character, so he ends up as a big blue dot in the center of the diagram. The lines between nodes indicate two actors that appeared simultaneously, and the line thickness reflects how much time the characters appear together. I used Gephi to compose the diagram. Gephi's layout and clustering algorithms positioned the nodes and colored the nodes and edges. I'm not sure how well the clustering and coloring represent actual cliques of characters in the film.

